|
I am a Ph.D. student in the Machine Learning Department at Carnegie Mellon University, where I am fortunate to be advised by Professor Andrej Risteski. Previously, I spent four wonderful years at the University of Illinois at Urbana-Champaign, completing my bachelor's degree in Statistics & Computer Science, as well as Mathematics. I am grateful for the mentorship of Professor Jiawei Han, Professor AJ Hildebrand, and Professor Pramod Viswanath. In fall 2024, I was a visiting graduate student for the Modern Paradigms in Generalization program at Simons Institute for the Theory of Computing. In the industry, I spent some exciting time at Microsoft (summer 2024), Google (summer 2023), ByteDance (TikTok) (summer 2022), Quora (2019-2020), and Facebook (Meta) (summer 2018).
Email / CV (resume) / LinkedIn / Google Scholar / Twitter (X) / GitHub / Quora |

|
|
I study machine learning, natural language processing, and data mining. I currently work on (1) improving mathematical understanding of language models (training dynamics, efficient sampling, mechanistic interpretability), and (2) developing principled approaches to self-supervised learning. For future work, I am broadly interested in large language models (LLMs) and related directions. My PhD work (published or ongoing) involve the following topics in language modeling research:
Prior to PhD, I worked on:
Please refer to the section below for my published papers and their accompanying resources (e.g. summaries, codes, slides, and video presentations). |
|
In the following list, the asterisk symbol (*) in the author list means equal contribution or alphabetical order. |

|
Dhruv Rohatgi, Abhishek Shetty, Donya Saless, Yuchen Li, Ankur Moitra, Andrej Risteski, Dylan J. Foster arXiv, 2025 bibtex We introduce a new process-guided test-time sampling algorithm for language models, VGB, which uses theoretically grounded backtracking to achieve provably better robustness to verifier errors. VGB interprets autoregressive generation as a random walk on a tree of partial generations, with transition probabilities guided by the process verifier and base model; crucially, backtracking occurs probabilistically. This process generalizes the seminal Sinclair-Jerrum random walk (Sinclair & Jerrum, 1989) from the literature on approximate counting and sampling in theoretical computer science. Empirically, we demonstrate on both synthetic and real language modeling tasks that VGB outperforms baselines on a variety of metrics. |
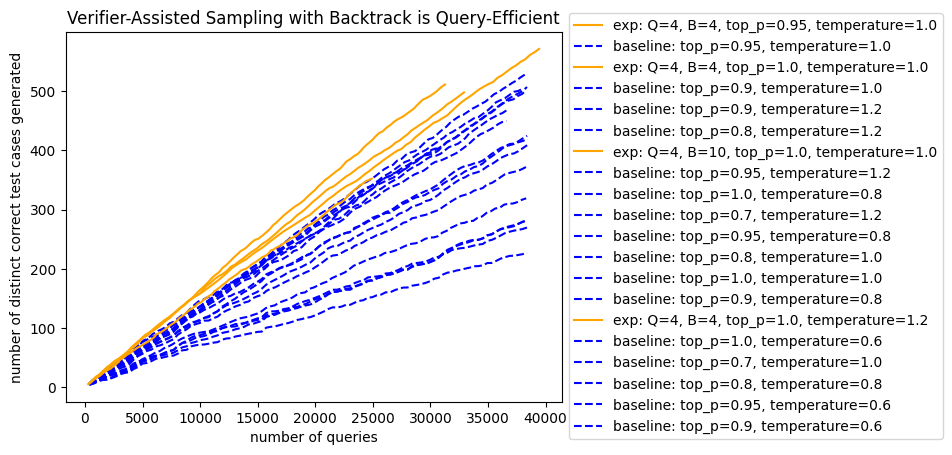
|
Edoardo Botta*, Yuchen Li*, Aashay Mehta*, Jordan T. Ash, Cyril Zhang, Andrej Risteski International Conference on Machine Learning (ICML), 2025 bibtex / slides / codes / Twitter summary / video recording of 5-minute talk In this paper, we develop a mathematical framework for reasoning about constrained generation using a pre-trained language model generator oracle and a process verifier--which can decide whether a prefix can be extended to a string which satisfies the constraints of choice. We show that even in very simple settings, access to a verifier can render an intractable problem (information-theoretically or computationally) to a tractable one. In fact, we show even simple algorithms, like tokenwise rejection sampling, can enjoy significant benefits from access to a verifier. Empirically, we show that a natural modification of tokenwise rejection sampling, in which the sampler is allowed to "backtrack" (i.e., erase the final few generated tokens) has robust and substantive benefits over natural baselines (e.g. (blockwise) rejection sampling, nucleus sampling)--both in terms of computational efficiency, accuracy and diversity. |
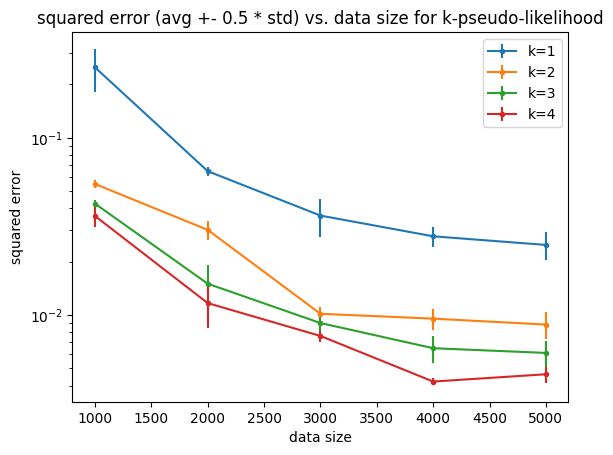
|
Yuchen Li, Alexandre Kirchmeyer*, Aashay Mehta*, Yilong Qin*, Boris Dadachev*, Kishore Papineni*, Sanjiv Kumar, Andrej Risteski International Conference on Machine Learning (ICML), 2024 also, ICLR Workshop on Bridging the Gap Between Practice and Theory in Deep Learning, 2024 (oral) bibtex / slides / codes / Twitter summary We establish a mathematical framework for understanding the potentials of applying masked language models (MLMs) to generative tasks. We theoretically analyze the training sample efficiency and the inference efficiency, and empirically characterize the critical components and failure modes. The highlight of our theory is a "dictionary" between the sample efficiency of MLM losses and the mixing times of Markov Chains. As a side product, we show that masking more is always statistically better (but algorithmically harder). Our theory also implies that "multimodal" distributions cause problems for both learning and inference. Finally, we theoretically identify a limitation of Transformers for parallel decoding: they enforce conditional product distributions, which can prevent fast mixing at inference time. We empirically validate our theory on synthetic and real data. |
|
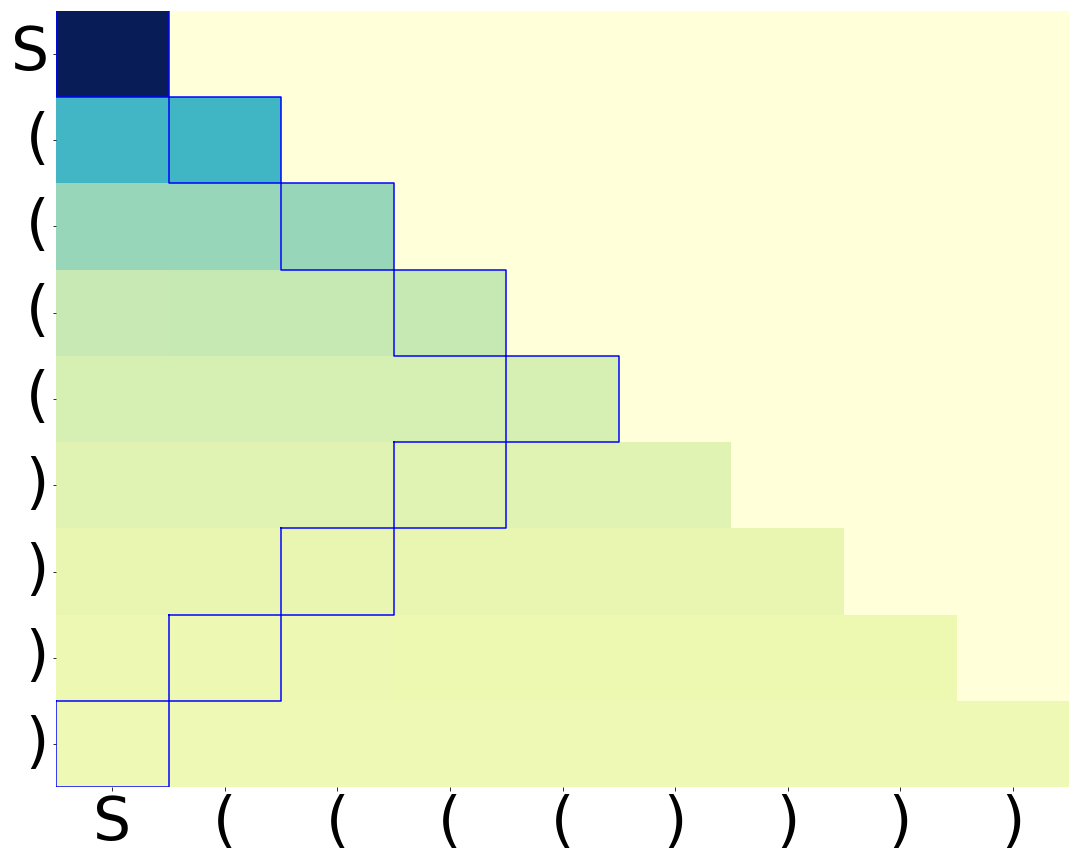
Kaiyue Wen, Yuchen Li, Bingbin Liu, Andrej Risteski Conference on Neural Information Processing Systems (NeurIPS), 2023 bibtex / slides / codes download / Twitter summary / video recording of 15-minute talk (starts at 5:39:20) We show that interpretability claims based on isolated attention patterns or weight components can be (provably) misleading. Our results are based on next-token prediction on Dyck (i.e. balanced brackets). We show that Transformers (exactly or approximately) solving this task satisfy a structural characterization, “balance condition“, derived from ideas in formal languages (the pumping lemma). |
|
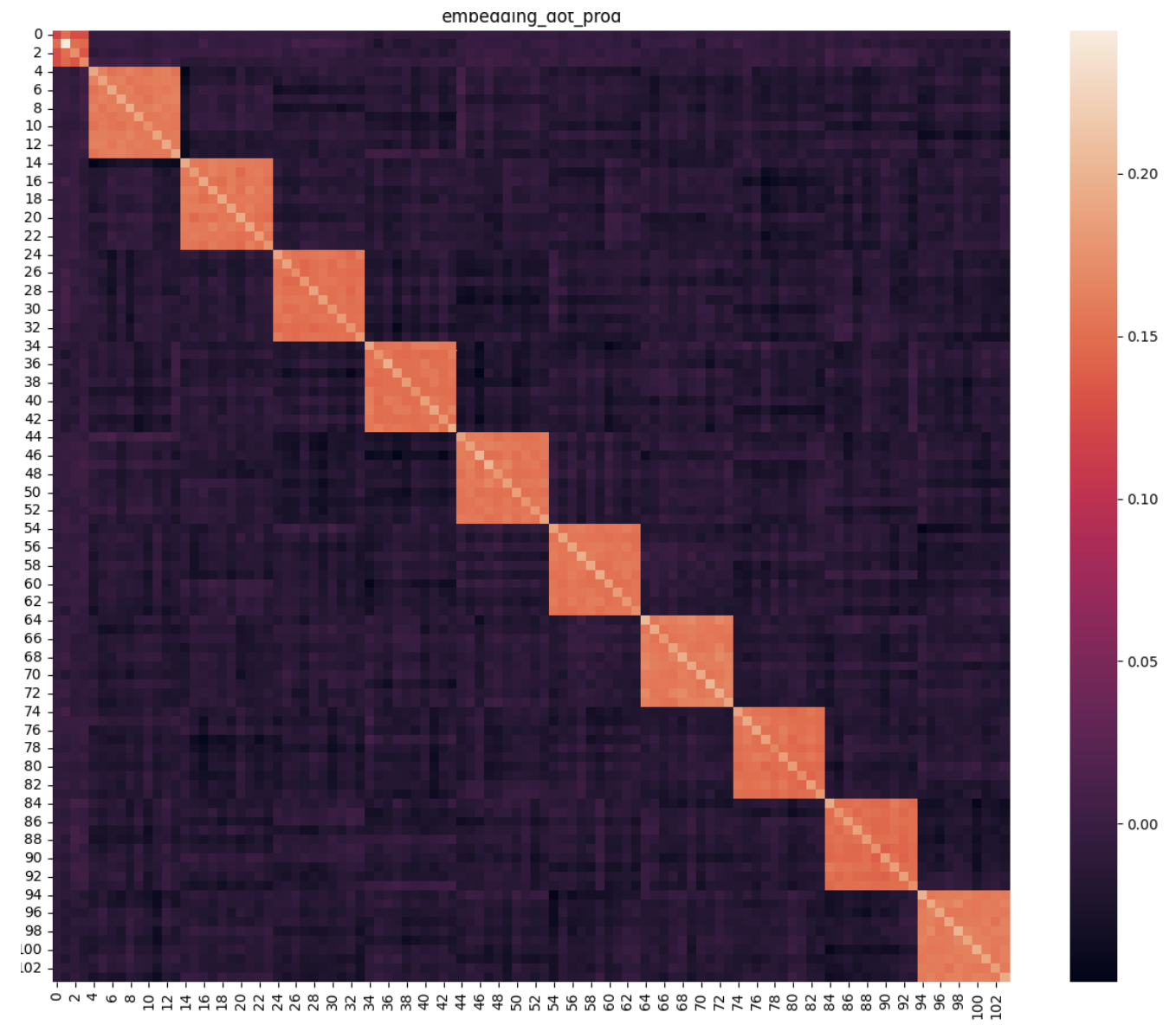
Yuchen Li, Yuanzhi Li, Andrej Risteski International Conference on Machine Learning (ICML), 2023 bibtex / slides / Twitter summary / project page / codes We analyze the optimization process of transformers trained on data involving "semantic structure", e.g. topic modeling. Through theoretical analysis and experiments, we show that between same-topic words, the embeddings should be more similar, and the average pairwise attention should be larger. In particular, we observe that with carefully chosen initialization and learning rate, the optimization process of self-attention can be approximately broken down into two stages: in stage 1, only the value matrix changes significantly; in stage 2, the key and query matrices catch up much later, even though all components are jointly optimized through standard SGD or Adam. This observation might be of independent interest, for future works on understanding the learning dynamics of transformers as well. |
|
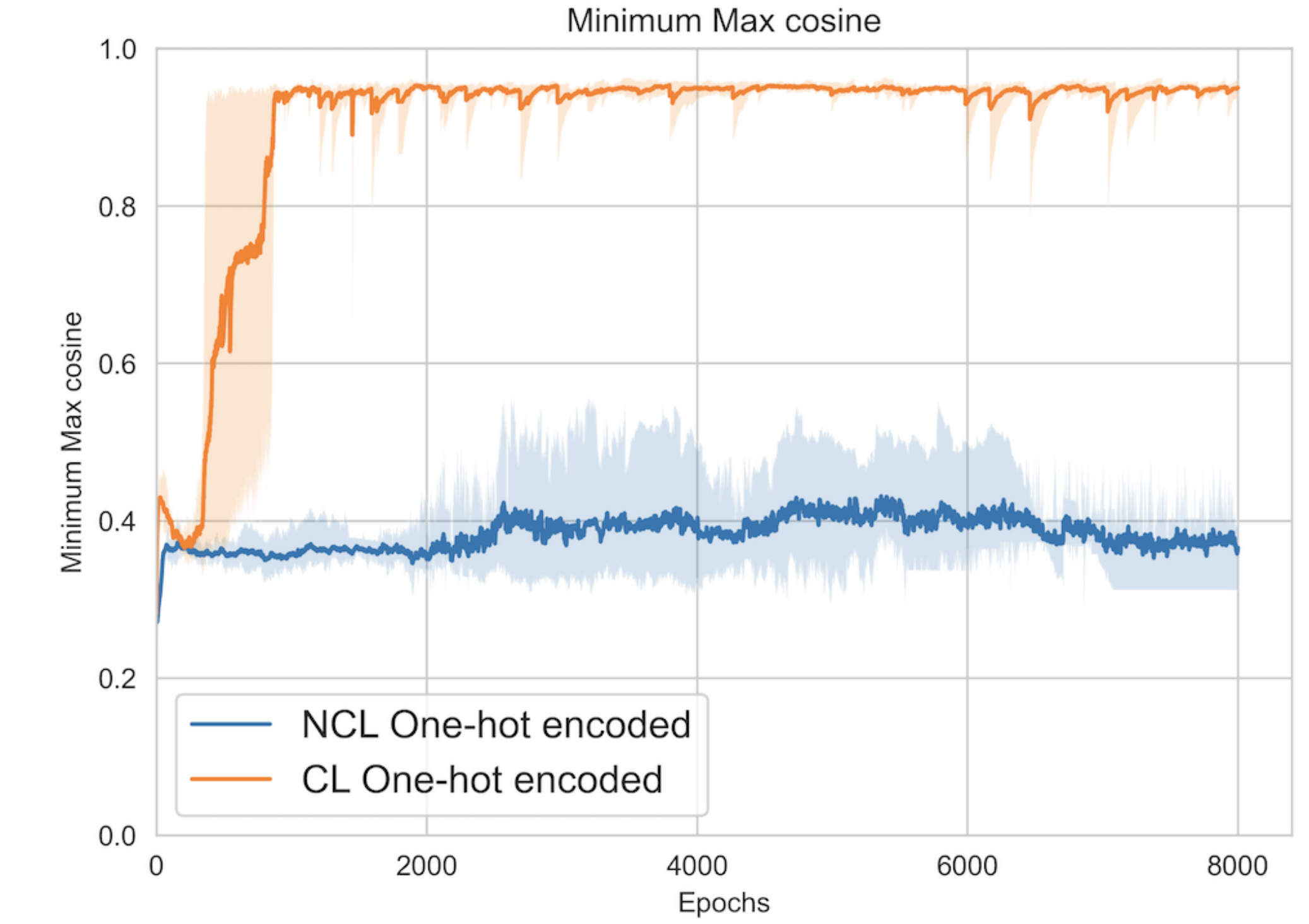
Ashwini Pokle*, Jinjin Tian*, Yuchen Li*, Andrej Risteski Conference on Artificial Intelligence and Statistics (AISTATS), 2022 bibtex / Twitter summary We show through theoretical results and controlled experiments that even on simple data models, non-contrastive losses have a preponderance of non-collapsed bad minima (which do not exist for their contrastive loss counterpart). Moreover, we show that the training process does not avoid these minima. |
|
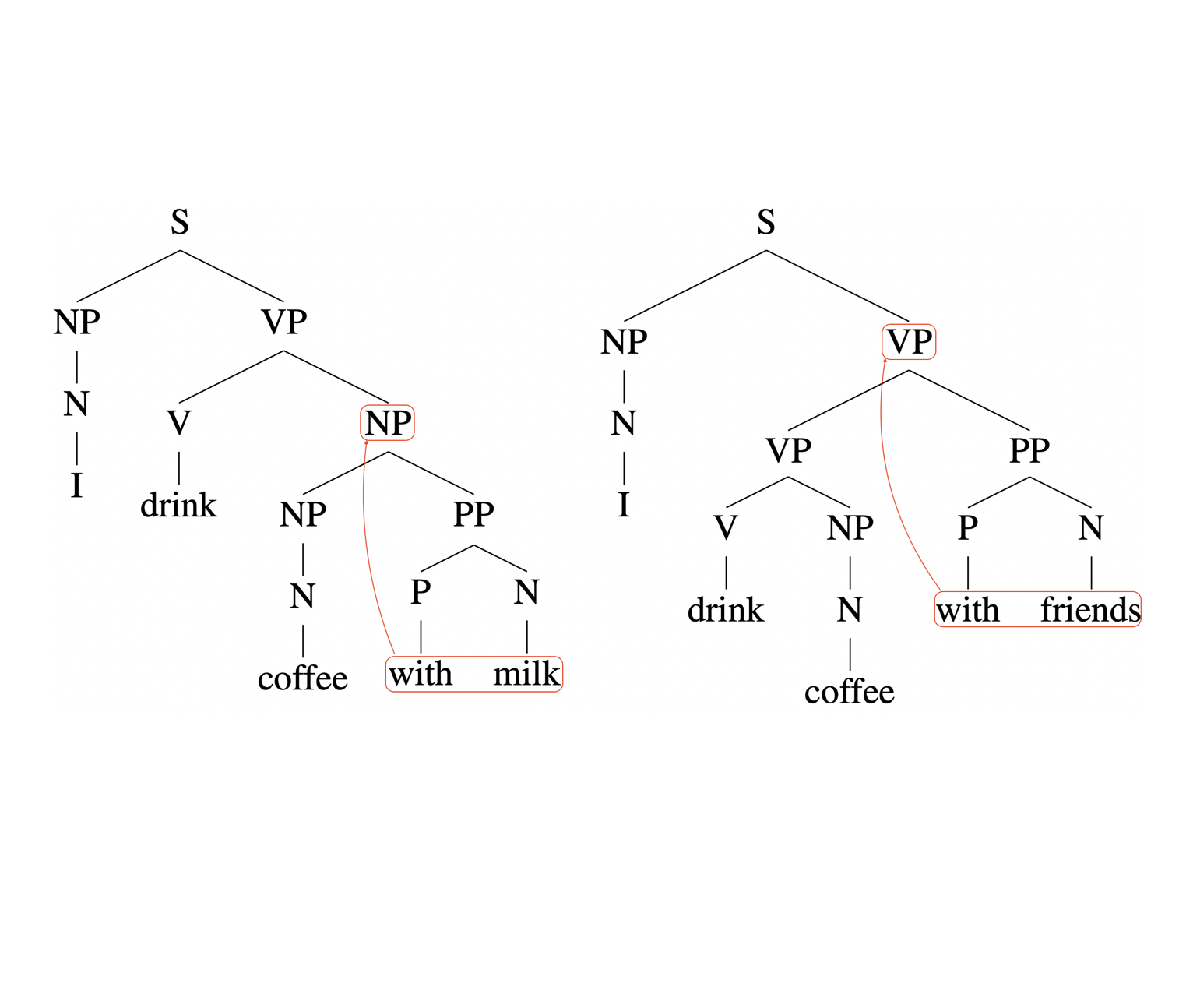
Yuchen Li, Andrej Risteski Association for Computational Linguistics (ACL), 2021 bibtex / slides / Twitter summary / Andrej's Tweet / blog post We prove that, if the context for the parsing decision at each word is unbounded & bidirectional, then the parsing model has full representational power. On the other hand, even if the context is bounded in one direction (which is the case for various leading approaches to constituency parsing), the parsing power is quite limited for hard grammars. |
|
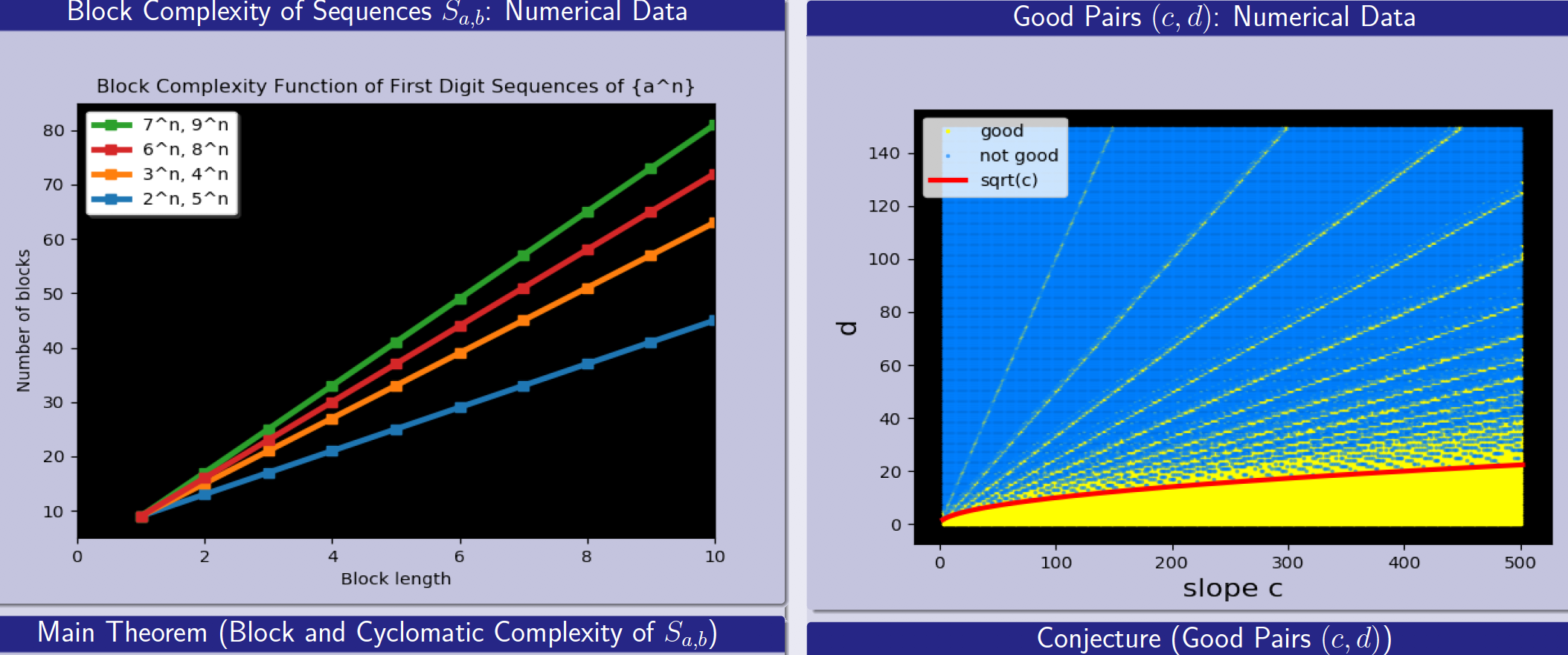
Xinwei He*, AJ Hildebrand*, Yuchen Li*, Yunyi Zhang* Journal of Discrete Mathematics & Theoretical Computer Science (DMTCS), vol. 22 no. 1, Automata, Logic and Semantics, 2020 bibtex / poster Consider the sequence of leading digits of 2^n: 1, 2, 4, 8, 1, 3, 6, ...... What is the complexity of such sequences? They are neither periodic nor random. How to quantify and distinguish the middle ground? We prove that, the block complexity is linear for the sequence of leading digits of a^n in base b (except for some special cases). In fact, we give explicit formula for the linear coefficients in terms of a and b. |
|
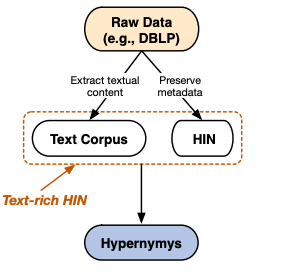
Yu Shi*, Jiaming Shen*, Yuchen Li, Naijing Zhang, Xinwei He, Zhengzhi Lou, Qi Zhu, Matthew Walker, Myunghwan Kim, Jiawei Han Conference on Information and Knowledge Management (CIKM), 2019 bibtex This work discovers hypernym-hyponym ("is-a" relation) pairs by an innovative combination of information from natural language and graph structure. Our system outperforms existing methods that utilize signals from text, graph, or both. |
|
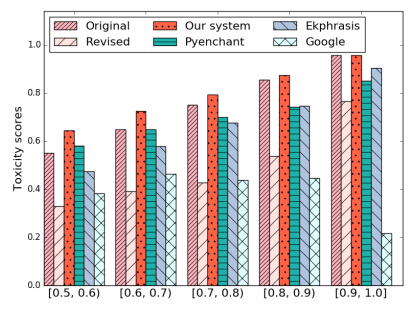
Hongyu Gong, Yuchen Li, Suma Bhat, Pramod Viswanath The Web Conference (WWW), 2019 bibtex Given a misspelled word, our algorithm generates candidates based on the surface form, represents the context as a linear space, and selects the candidate whose embedding is closest to the context subspace. The spelling correction accuracy is better than the state-of-the-art methods, improving the performance in downstream applications. |
|
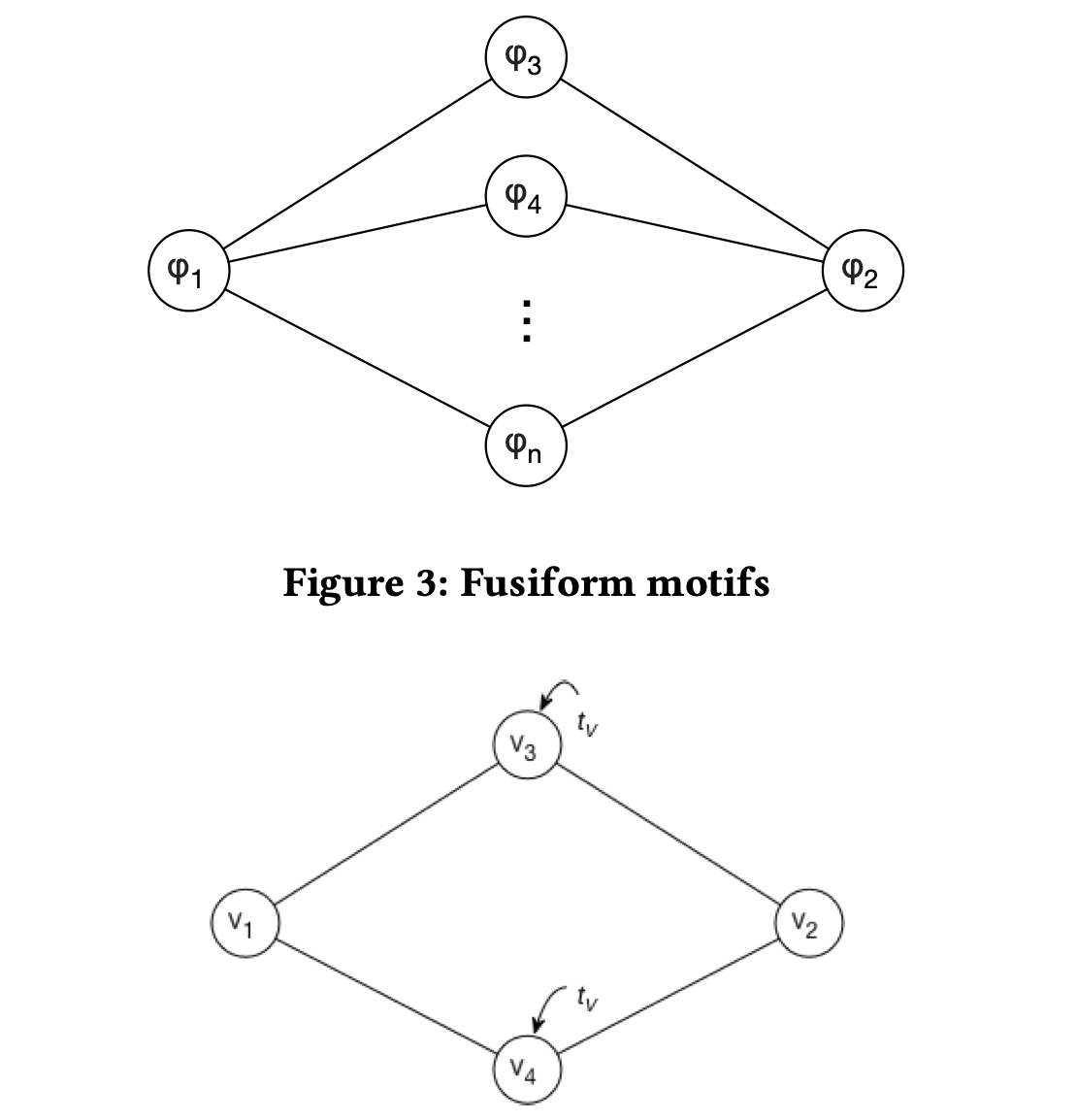
Yuchen Li*, Zhengzhi Lou*, Yu Shi, Jiawei Han Workshop on Mining and Learning with Graphs (MLG), in conjunction with KDD, 2018 bibtex This work shows the effectiveness of temporal motifs (frequent substructures) in quantifying the relationship between nodes in heterogeneous information networks, and proposes efficient algorithms for counting a family of useful motifs. |
|
|
|
|
|
Role: Teaching Assistant Course Webpage: This URL Instructor: Nihar Shah |
|
Role: Teaching Assistant Course Webpage: This URL Instructors: Andrej Risteski and Hoda Heidari |
|
Template of this page: credit to: link. |